Colindancias 10 / 2019, 239-263
Vlatka Rubinjoni Strugar
Universidad
de Alcalá
La relación del artículo
con los demostrativos
y los posesivos en función
de los errores que cometen
los estudiantes serbios de español
Recibido: 11.11.2019 / Aceptado:
13.12.2019
1.
Introducción
El presente
artículo se apoya en una investigación doctoral que indaga los errores en el uso del artículo
determinado que cometen
estudiantes serbios de español de primer, segundo, tercer
y cuarto curso de licenciatura. Dicha tesis doctoral, que lleva por título Análisis de
errores en el uso del artículo determinado en producciones escritas de
aprendientes serbios de español, se
enmarca en un conjunto de investigaciones sobre análisis de errores
que se han llevado a cabo en el Área de Lingüística General del Departamento de Filología, Comunicación y
Documentación de la Universidad de
Alcalá, bajo la dirección de la profesora Penadés
Martínez. Los objetivos del estudio son los siguientes: a) realizar un contraste entre las funciones del artículo determinado español y los mecanismos que
el serbio utiliza para determinar la referencia del sustantivo, siempre en función de los
tres niveles de competencia (A, B y C); b) registrar los errores en el uso del artículo
determinado con el fin de realizar una estadística de los usos correctos
e incorrectos; c) encontrar las causas de los
errores mediante los dos métodos de
la lingüística contrastiva, el análisis contrastivo y el análisis
de errores; d) ofrecer y enfocar los resultados del análisis de tal modo que puedan servir para subsanar
los errores en el uso del artículo
determinado.
La metodología de la investigación ha consistido en realizar primeramente
un análisis contrastivo y, más tarde,
un análisis de errores en producciones escritas de estudiantes serbios
de español para comprobar la hipótesis derivada
del contraste de las
lenguas, que consiste en predecir las áreas de dificultad que generarían error durante el proceso de aprendizaje
de una lengua extranjera y que considera que
son fáciles de aprender las estructuras que son similares, y difíciles
las que son diferentes. Ambos
procedimientos de análisis los hemos organizado por niveles de competencia, siguiendo el Plan curricular del Instituto Cervantes
(2006), así como
a Martí Sánchez, Penadés Martínez
y Ruiz Martínez (2008) y su Gramática española
por niveles. Para realizar el análisis contrastivo, hemos buscado
las equivalencias en serbio a partir
de los contenidos españoles establecidos por el PCIC. Para realizar el análisis de errores, hemos cuantificado
los usos erróneos y los correctos; dentro de
los usos erróneos
hemos sumado los errores de omisión, adición
y falsa selección. Los
errores de omisión los hemos clasificado por contenidos y niveles siguiendo el PCIC; de manera análoga, hemos clasificado los errores de adición y los errores
de falsa selección1. Los errores
de falsa selección, que son el tema de este escrito,
pertenecen al Nivel A de referencia,
según el PCIC; no obstante, hemos examinado sus
ocurrencias en producciones escritas de estudiantes serbios de español de todos los años de estudio, con el fin de
averiguar si con el tiempo su índice disminuye
o si, por el contrario, aumenta. Asimismo, nos interesaba examinar
cuáles son los contenidos
que más dudas causan a estos estudiantes y si en los años superiores resuelven o no las cuestiones problemáticas. Hemos investigado la falsa selección del artículo en lugar de otros determinantes (artículo
indeterminado, demostrativo, posesivo,
etc.), así como el caso inverso, la selección errónea de otros determinantes en vez del artículo
determinado.
Cabe añadir
que, con el fin de averiguar si distintos temas
en corpus escritos
producen idénticos problemas, hemos
trabajado con dos corpus iguales en estructura
y diferentes en cuanto
al tema de redacción: uno, el 2014, con un tema académico, Comenta, de manera
razonada, qué asignaturas y qué contenidos de la Licenciatura te resultan más interesantes y cuáles son los que no te interesan (94 redacciones), y otro, el 2011, con un tema libre sobre los viajes, El viaje de mis sueños (102 redacciones). El corpus 2014
1 Una información extensa sobre los errores de omisión y adición, así como de falsa selección,
se puede encontrar en el libro El serbio,
una muestra para lenguas sin artículo determinado de Vlatka Rubinjoni Strugar (2018).
fue confeccionado por nosotros
en la Universidad serbia de Kragujevac; el corpus
2011 fue creado
por la profesora Gorana Zečević Krneta en la misma Universidad de Kragujevac y forma parte de su
tesis doctoral (2016). Los dos corpus fueron
realizados, pues, en la misma
institución universitaria; no obstante, difieren en el tema de la redacción que se solicitó
a los estudiantes.
El cómputo y la estadística de los errores de falsa selección han mostrado
que el mayor problema para el estudiante serbio de español
es la relación entre el artículo determinado
y el determinante posesivo, así como la relación entre el artículo determinado y el determinante demostrativo. Debido a ese hecho,
se examinan los resultados del análisis de los errores de falsa
selección en producciones escritas de estudiantes serbios
y se muestran los mayores
problemas que tienen
estos informantes. Asimismo, se ofrecen las causas de los errores
y se proponen procedimientos que sirvan
para subsanarlos, siguiendo los dos métodos de la lingüística contrastiva, el análisis contrastivo y el análisis
de errores. El presente escrito
se cierra con las conclusiones
que resumen las causas principales de los problemas más pronunciados que muestran estudiantes serbios al
seleccionar el artículo determinado en lugar de otro determinante o al seleccionar otro determinante en vez del artículo determinado.
2. Análisis de los errores de falsa selección
Con el fin de
analizar ambos corpus durante nuestra investigación doctoral, hemos
establecido, en primer lugar, una clasificación general de los errores según el criterio lingüístico (Vázquez 1991),
descriptivo (Santos Gargallo 1993) o estratégico (Fernández 1997) de omisión, adición y falsa selección
con respecto a otros determinantes
(el artículo indeterminado, el demostrativo el posesivo, etc.). Los errores
de omisión, adición y falsa selección, que corresponden a contenidos de los distintos niveles de competencia (A1-A2,
B1, B2 y C1, respectivamente), los hemos separado por corpus (corpus
2014 y corpus 2011) y por cursos
(I, II, III y IV). En segundo lugar,
hemos realizado clasificaciones específicas de los errores de omisión, adición y falsa selección,
siguiendo el esquema por contenidos según los niveles de competencia del Plan curricular del Instituto Cervantes (2006)
y la Gramática española por niveles de Martí Sánchez, Penadés
Martínez y Ruiz Martínez (2008). Por lo que respecta
a la subdivisión de los errores de falsa selección, que corresponden al Nivel A
de competencia, hemos establecido dos tablas que tienen la misma distribución por categorías gramaticales;
no obstante, una está destinada a los ejemplos de falsa selección del artículo
determinado en lugar de otro determinante (A), mientras que la otra está destinada
a registrar errores
en el uso de otros determinantes en vez del artículo determinado (B).
A partir de estas clasificaciones, una general que observa los errores de omisión, adición y falsa selección, y otra más
específica que se vale de las subdivisiones por cada categoría del error, hemos ido discriminando la incidencia del error a la vez que
hemos contabilizado los datos obtenidos y, finalmente, hemos realizado una estadística
de la incidencia del error. De manera paralela, hemos ido confeccionando gráficos
para cada tipo de error y para todos en conjunto, ya que consideramos que la presentación visual ayuda a una mejor y más rápida percepción de los datos. El objetivo final de la investigación ha sido aunar
los dos métodos
de investigación, el análisis contrastivo y el análisis de
errores, para encontrar las causas de estos errores,
así como su posible erradicación a través de una implicación didáctica. A continuación, se presentan los resultados del análisis de los errores
de falsa selección, de tal modo que primeramente se exponen los resultados
de la investigación del corpus 2014 (apartado 2.1), después del corpus 2011
(apartado 2.2) y, finalmente, se presenta
una recapitulación de los errores de falsa selección en ambos corpus al final de los estudios (apartado 2.3).
2.1
El cómputo
y la estadística de los errores de falsa selección, corpus 2014
Con el fin de
establecer cuáles son los errores de falsa selección que más problemas
causan a los informantes del corpus 2014, hemos realizado cómputos de estos errores y hemos elaborado
gráficos que los representan. Los gráficos los hemos realizado de modo que el color rojo
representa los errores del primer curso, es decir, que refleja contenidos del Nivel A (2.1.1). Los errores de falsa selección
que aparecen en el segundo curso de los estudios los
presentamos en color violeta. Se trata, en este caso, de errores que se han quedado fosilizados del año
anterior (2.1.2). La siguiente sección de este apartado lleva por título Recopilación de los errores de falsa
selección del I al IV año,
corpus 2014 (2.1.3). El objetivo de
esta recopilación es averiguar cómo avanza esta problemática en el transcurso de los cuatro
cursos. Debido a eso, presentamos dos gráficos paralelos, uno con valores y otro con tendencias.
Asimismo, nos interesaba examinar si todos los cursos coinciden en tener determinados
contenidos problemáticos, por lo que hemos elaborado un gráfico
Puntos en común del I al IV año, corpus 2014 que refleja los problemas que comparten juntos el primer,
el segundo, el tercer y el cuarto
curso.
La parte importante de este análisis es justificar cada clase de error con
algún ejemplo del corpus
y determinar la causa del mismo a partir del contraste entre
el español y el serbio.
Junto con la causa del error, nos interesaba determinar si este podría
ser previsto por el análisis
contrastivo o, en el caso de que el análisis
de los errores lo demuestre, si el error se debe a otra etiología.
2.1.1
Errores de falsa selección
del I año, corpus 2014
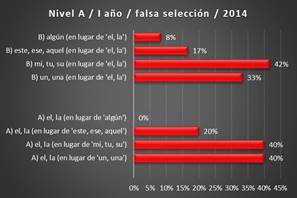
Presentamos, a
continuación, la falsa selección del artículo determinado en lugar de otro determinante (A) y la falsa
selección de otro determinante en lugar del artículo determinado (B) en la tabla y en el
gráfico de color rojo debido a que se trata
de las materias que corresponden al Nivel A, nivel en el que se encuentran los estudiantes.
|
A. Selección del artículo determinado en lugar
de otro determinante
|
Valor del error
en porcentajes
|
|
el, la (en lugar
de un, una)
|
40 %
|
|
el, la (en lugar
de mi, tu, su)
|
40 %
|
|
el, la (en lugar
de este, ese,
aquel)
|
20 %
|
|
el, la (en lugar
de algún, alguna)
|
0 %
|
|
B. Selección de otro determinante en lugar
del artículo determinado
|
Valor del error
en porcentajes
|
|
un, una (en lugar
de el, la)
|
33 %
|
|
mi, tu, su (en lugar
de el, la)
|
42 %
|
|
este, ese, aquel (en lugar
de el, la)
|
17 %
|
|
algún, alguna (en lugar
de el, la)
|
8 %
|
Tabla 1. Errores de falsa selección, I año, corpus
2014 (Fuente: VRS2)
Gráfico 1. Errores
de falsa selección, corpus 2014 (Fuente:
VRS)
2 Todas las tablas, así como los gráficos, están
realizados por la autora, de ahí que se señalen
con sus iniciales VRS.
El cómputo
y la estadística de los errores de falsa selección muestran que el mayor problema reside en la relación entre el
artículo determinado y el determinante posesivo,
pues el 42 % de todos los errores pertenecen a la falsa selección del determinante posesivo en lugar del
artículo determinado (B), mientras que la situación
inversa, la selección
del artículo determinado en lugar del determinante posesivo (A), llega al 40 %.
Consideramos que la causa de la falsa selección del determinante posesivo
en lugar del artículo (B, 42 %), reside, además
de en el desconocimiento de las reglas en español, en la interferencia de otras
lenguas extranjeras que el estudiante conoce3, puesto
que el serbio en contextos análogos no usa el posesivo. Presentamos, a continuación,
un texto con el error marcado del corpus 2014, su versión correcta en serbio
con la traducción al español
palabra por palabra
y, asimismo, la traducción del serbio al inglés:
Porque sé que si no aprendo
eso ahora, en el principio,
voy a tener un gran problema y
dudo que podría
resolverlo después, también acabar *mis estudios en tiempo definido4.
En serbio:
Jer znam da ako to ne
naučim sada, na početku, imaću
veliki problem i sumnjam da ću kasnije moći da ga rešim, niti da završim studije u određenom roku.
“Porque sé que, si eso no aprendo ahora,
al inicio, tendré
gran problema y dudo que
seré más tarde capaz de lo resolver, tampoco
que terminar estudios
en definido plazo.”
En inglés:
Because I know that if I do not
learn it now, at the beginning,
I will have a big problem and I doubt that I would later be able to solve it, not even to finish my studies within a certain period of time.
En las
traducciones presentadas, se observa que el inglés utiliza el posesivo my en my studies, mientras
que el serbio no lo usa en studije (‘estudios’), por lo que la transferencia negativa
en *‘mis estudios’ es del inglés
y no del serbio.
3 La encuesta
que realizamos con los informantes del corpus 2014 muestra que todos los
estudiantes de la facultad se han matriculado con conocimientos previos de una
o varias lenguas extranjeras, de las cuales
el inglés es la más frecuente.
4 Corpus 2014/I, redacción 28/I.
Por lo que se refiere
a la situación inversa, la selección del artículo determinado en lugar del
determinante posesivo (A), el cómputo refleja el 40 % del total de los errores. La causa de estos errores
reside en el desconocimiento de las reglas en
español. Según Leonetti, para que el artículo
aparezca en lugar del posesivo, el poseedor
debe estar reflejado
en un constituyente externo al sintagma nominal
definido (2000: 809). En los errores cometidos
por los estudiantes serbios no hay transferencia
negativa de la lengua materna porque el serbio, en contextos análogos, aplica normas equivalentes a las
españolas, es decir, utiliza el posesivo. Presento un ejemplo del corpus
2014:
Los clases de la historia hispanoamericana están interesantes también para mí, porque quiero
conocer bien los lugares que existen en España y *las personas
famosas también5.
En serbio:
Časovi hispanoameričke istorije su takođe intersantni za mene, jer želim dobro da upoznam mesta koja postoje u Španiji kao i njene6 poznate ličnosti.
“Clases hispanoamericana historia son también interesantes para mí, porque quiero
bien a conocer sitios que existen en España como y sus famosos personajes.”
En la traducción al serbio y en su traducción palabra por palabra al
español, se observa que el serbio
usa el posesivo njene, ‘sus’,
al igual que lo utiliza
el español en ‘sus personajes famosos’.
Otro grupo relevante para la investigación atañe a la relación entre el
artículo determinado y el determinante demostrativo. El 20 % de los errores es relativo al uso del artículo determinado en lugar del determinante demostrativo (A). La causa
5 Corpus
2014/I, redacción 1/I.
6 El vocablo njene (‘sus’)
es un pronombre posesivo que indica
que el poseedor es de tercera persona femenino
singular porque el poseedor, Španij-i, ‘España’,
es un sustantivo de tercera
persona femenino singular.
Al mismo tiempo
indica que el objeto poseído
es de género femenino en plural
porque ličnosti,
‘personajes’, en serbio es un sustantivo femenino en plural. Cabe añadir que el serbio distingue entre el pronombre posesivo personal (njen) y el pronombre posesivo reflexivo (svoj). Contrastando el español y el serbio
en Claudia dice que María había cerrado los ojos y en Claudia
dice que María había cerrado sus ojos, el serbio usa el pronombre
posesivo reflexivo en el primer caso (Klaudija kaže da je Marija zatvorila svoje oči, “Claudia
dice que María había cerrado los ojos”); y en el segundo, utiliza el pronombre posesivo
personal (Klaudija kaže da je Marija zatvorila njene oči, “Claudia dice que
María había cerrado sus ojos”).
de estos errores es el
desconocimiento de las reglas gramaticales. En español, según Leonetti, la diferencia más evidente entre el uso del demostrativo frente al uso del artículo determinado consiste en que el
demostrativo exige que el referente sea perceptible de alguna forma en la situación de habla (2000:
800). En serbio,
según Piper
y Klajn, los demostrativos ovaj (‘este’), taj (‘ese’) y onaj (‘aquel’) pueden designar un
elemento previamente mencionado en el discurso o algo que permanece en la memoria de los interlocutores (función
anafórica) (2014: 103-106).
De ahí que no haya interferencia del serbio, debido a
que esta lengua en contextos equivalentes también
usa el demostrativo. Presentamos a continuación un ejemplo del corpus 2014:
Las clases con nuestra
profesora al principio me parecían muy aburridos, pensaba que tenemos demasiadas cosas para aprender,
tanto palabras como reglas, pero después empecé
a querer *la asignatura7.
Časovi sa našom profesorkom su mi u početku izgledali dosadni, mislila sam da imamo previše stvari za učenje, kako reči tako pravila, ali posle sam zavolela taj predmet.
“Clases con nuestra profesora a mí al principio
parecían aburridos, pensaba que tenemos demasiadas cosas para aprender,
tanto palabras como reglas, pero después llegué
a querer esa asignatura.”
En español, la versión correcta, ‘esa asignatura’, es equivalente al
serbio, taj predmet (‘esa asignatura’), es decir, ambas lenguas
usan el demostrativo: el español, porque el referente es perceptible en el
discurso; el serbio, porque se vale de la función anafórica
de sus demostrativos.
En cuanto a la
situación inversa (B), el uso del demostrativo en lugar del artículo, consideramos que la causa reside
en la interferencia de la lengua materna
además de en el desconocimiento de las
normas del español: el estudiante se vale de
la función anafórica de los demostrativos ovaj (‘este’), taj (‘ese’) y onaj (‘aquel’), y la aplica al español.
La obra que más me gusta, de *estos que habíamos leído, es La Celestina8. Delo koje mi se najviše sviđa, od on-ih koje
smo čitali, je La Selestina.
“Obra que a mí me más gusta, de aquellos que hemos leído, es La Celestina.”
7 Corpus 2014/I, redacción 14/I.
8 Corpus 2014/I,
redacción 17/1.
En el presente ejemplo,
el estudiante ha utilizado el demostrativo *‘estos’
valiéndose de la función anafórica
de los demostrativos serbios. Por otro lado, desconoce la norma del español de que los demostrativos no pueden emplearse en primera mención si el sustantivo al que determinan va con modificadores restrictivos.
Resumiendo los errores de falsa selección y sus causas, se infiere que la
causa de la falsa selección del artículo determinado en lugar
de otro determinante (A) reside en el
desconocimiento de las reglas. No obstante, cuando el aprendiente utiliza algún determinante en lugar del artículo determinado (B), la causa reside en la interferencia de su lengua materna o de otra lengua extranjera que conoce, además
de en el desconocimiento de las reglas de uso del artículo
determinado.
2.1.2
Errores de falsa selección
del II año, corpus 2014
El corpus 2014 muestra
que los estudiantes del segundo curso han superado
varios problemas, por lo que el número
de los errores ha bajado sustancialmente. Presentamos a continuación su distribución en la tabla y en el gráfico que siguen.
|
A. Selección del
artículo determinado en lugar
de otro determinante
|
Valor del error en porcentajes
|
|
el, la (en lugar
de un, una)
|
0 %
|
|
el, la (en lugar
de mi, tu, su)
|
100 %
|
|
el, la (en lugar
de este, ese,
aquel)
|
0 %
|
|
el, la (en lugar
de algún, alguna)
|
0 %
|
|
B. Selección de otro determinante en lugar
del artículo determinado
|
Valor del error
en porcentajes
|
|
un, una (en lugar
de el, la)
|
0 %
|
|
mi, tu, su (en lugar
de el, la)
|
67 %
|
|
este, ese, aquel (en lugar
de el, la)
|
33 %
|
|
algún, alguna (en lugar
de el, la)
|
0 %
|
Tabla 2. Errores fosilizados de falsa selección, II año, corpus
2014 (Fuente: VRS)
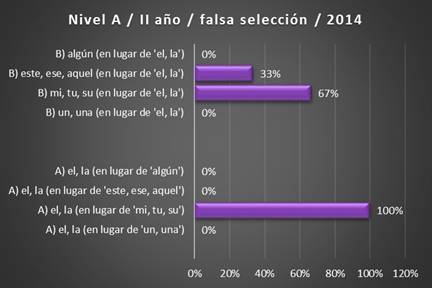
Gráfico 2. Errores fosilizados de falsa selección, II año, corpus
2014 (Fuente: VRS)
Los cálculos y el
gráfico muestran que dentro del grupo A), es decir, la selección del artículo
determinado en lugar de otro determinante, el único problema se
presenta con la selección del artículo en lugar del posesivo, por lo que su valor
porcentual es del 100 %. Por lo que se refiere a los errores
del grupo B), es decir,
la selección de otro determinante en lugar del artículo determinado, el 67 % de los errores
son causados por la selección del posesivo en lugar del artículo. Por otra parte, el 33 % de los errores
se deben a la falsa selección del demostrativo en lugar del artículo.
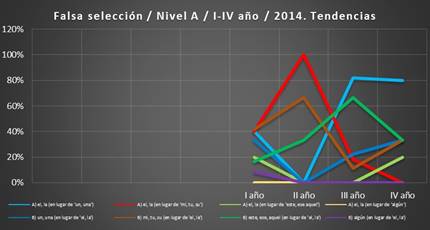
2.1.3 Recopilación de los errores de falsa selección, I-IV año, corpus
2014
Para completar
el análisis de los errores
de falsa selección
del corpus 2014,
hemos recopilado los errores del primer al cuarto
curso. El objetivo de esta recopilación es averiguar cómo avanza esta problemática desde el primer hasta el cuarto
curso. Nos interesaba averiguar si su porcentaje con el tiempo disminuía o, por el contrario, crecía. Hemos
determinado que los errores de falsa selección
presentan oscilaciones en todos los cursos.
En los gráficos siguientes presentamos los valores de sus ocurrencias, así como sus tendencias en el trascurso de los años
lectivos.
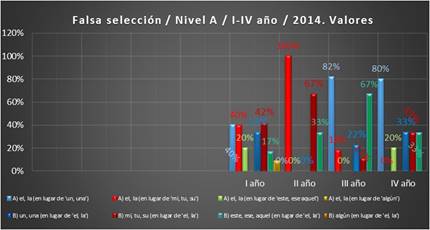
Gráfico 3. Valores. Falsa selección, I-IV año,
corpus 2014 (Fuente: VRS)
Gráfico 4. Tendencias. Falsa selección, I-IV año, corpus
2014 (Fuente: VRS)
El gráfico
de los valores, así como el de las tendencias, muestran que en el
segundo curso el mayor problema lo constituye la relación entre el artículo determinado y los posesivos, sobre todo la falsa selección del artículo en lugar del posesivo, el 100 %. Ya en el tercer curso este problema
disminuye, llegando al 18 %, y en el cuarto
desaparece por completo. Sin embargo, crece levemente la situación inversa,
la selección errónea del posesivo en lugar del artículo, por lo que el cuarto curso termina con un 33 % de estos errores. Por otro lado, en el tercer curso destaca
la falsa selección del artículo
determinado en lugar del indeterminado (82 %) y este problema se mantiene en el cuarto sin grandes cambios (80 %).
Los errores de falsa selección del
determinante demostrativo en lugar del artículo determinado suben del primer al segundo curso y culminan
en el tercero con un 67 %; en el cuarto curso
estos errores disminuyen al 33 %.
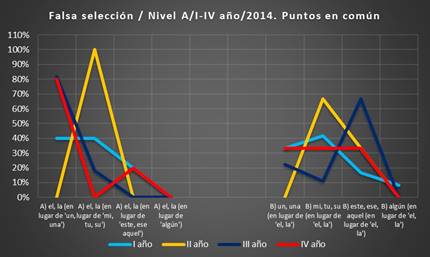
2.1.4
Puntos en común del primer al cuarto curso,
corpus 2014
Debido a que hemos observado que existen clases de errores de falsa
selección que inciden en todos los
años de estudio, hemos elaborado un gráfico para observar si todos los cursos
coinciden en tener determinados contenidos problemáticos. El objetivo de esta clasificación es observar qué contenidos producen
mayores dudas en todos los años de estudio del
presente corpus 2014. En el gráfico siguiente
presentamos los puntos
en común del primer al cuarto curso.
Gráfico 5. Puntos en común. Falsa
selección, I-IV año, corpus 2014 (Fuente: VRS)
Los errores
en los que coinciden todos los cursos
y aquellos en los que coinciden tres de los cuatro
años lectivos son los siguientes:
Grupo A), falsa selección del artículo determinado en lugar de otro determi-
nante:
-
Falsa
selección del artículo
determinado en lugar del indeterminado (40 %, 0 %, 82 % y 80 %).
-
Falsa selección
del artículo determinado en lugar del posesivo (40 %, 100 %, 18 % y 0 %).
Grupo B), falsa selección
de otro determinante en lugar del artículo determi-
nado:
- Falsa selección
del posesivo en lugar del artículo (42 %, 67 %, 11 % y 33 %).
- Falsa selección del demostrativo en lugar del artículo
(17 %, 33 %, 67 % y 33 %).
- Falsa selección del artículo indeterminado en lugar del artículo (33 %, 0 %, 22 % y 33
%).
2011
2.2 El cómputo y la estadística de los errores de falsa selección, corpus
Para mantener la coherencia de la investigación, hemos trabajado con el corpus
2011 siguiendo el
mismo procedimiento que aplicamos al corpus 2014; establecida la
clasificación general, hemos procedido a realizar las tablas y los gráficos que representan los errores de falsa selección
del siguiente modo: el color rojo representa los errores del I curso, es decir, refleja los
contenidos del Nivel A, nivel al que corresponden los errores de falsa selección
(2.2.1); el color violeta representa los errores del II
curso, es decir los errores que se han quedado fosilizados del año anterior (2.2.2). Para averiguar cómo
avanza el presente conjunto de problemas, hemos
recopilado los errores de falsa selección del primer al cuarto curso en una nueva
sección, Recopilación de los errores de
falsa selección del I al IV año, corpus 2011 (2.2.3); para examinar si todos los cursos
coinciden en tener determinados contenidos problemáticos, hemos elaborado el gráfico que
exponemos en la sección Puntos en común del I al IV año, corpus 2011 (2.2.4). Al igual que en el apartado sobre los
errores de falsa selección del
corpus anterior, hemos justificado cada clase de error con algún
ejemplo y hemos determinado la causa del error a partir del contraste entre el español y el serbio.
2.2.1
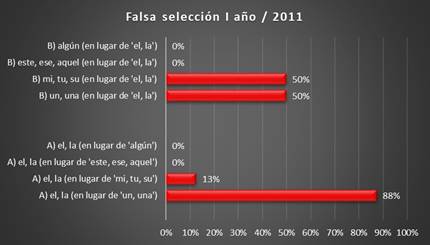
Errores de falsa selección, I año, corpus
2011
Presentamos las ocurrencias de los errores de falsa selección cometidos
por los informantes del corpus 2011
en la tabla y en el gráfico a continuación. Dado que se trata de las materias
que hay que considerar en clase de Nivel A, su representación gráfica
está en rojo.
|
A. Selección del artículo determinado
en lugar
de otro determinante
|
Valor del error
en porcentajes
|
|
el, la (en lugar
de un, una)
|
88 %
|
|
el, la (en lugar
de mi, tu, su)
|
13 %
|
|
el, la (en lugar
de este, ese,
aquel)
|
0 %
|
|
el, la (en lugar
de algún, alguna)
|
0 %
|
|
B. Selección de otro determinante
en lugar
del artículo determinado
|
Valor del error
en porcentajes
|
|
un, una (en lugar
de el, la)
|
50 %
|
|
mi, tu, su (en lugar
de el, la)
|
50 %
|
|
este, ese, aquel (en lugar
de el, la)
|
0 %
|
|
algún, alguna (en lugar
de el, la)
|
0 %
|
Tabla 3. Errores de falsa selección, I año, corpus
2011 (Fuente: VRS)
Gráfico 6. Errores de falsa selección, corpus 2011 (Fuente:
VRS)
La estadística de los errores de falsa selección muestra que el mayor
problema de los estudiantes del primer curso del corpus 2011
reside en la relación entre el artículo
determinado y el indeterminado; el 88 % son errores en la selección del artículo
determinado en lugar del indeterminado, mientras que el 50 % corresponde al caso inverso, la selección
del artículo indeterminado en lugar del determinado.
Por lo que respecta a la relación entre el artículo determinado y el
determinante posesivo, el mayor problema
lo causa la falsa selección
del determinante posesivo
en
lugar del artículo determinado (B),
el 50 % de los errores. La causa de estos errores es la interferencia de otra lengua extranjera, sobre todo del
inglés, cuando se trata de las
partes del cuerpo, porque el serbio en contextos análogos no utiliza el
posesivo. La oración escrita
por el estudiante serbio de español:
Al entrar sentí en *mi estómago pequeñas mariposas
y cuando subí al primer piso me
enamoré9.
En serbio será:
Kada sam ušla, osetila sam u stomaku male leptiriće, a kada sam se popela na prvi sprat
zaljubila sam se.
“Cuando entré, sentí en estómago pequeñas
mariposas y cuando
subí en primer piso
enamoré me.”
Mientras que en inglés será:
On entering I felt small butterflies in my stomach and when I went up to the first floor
I fell in love.
En las traducciones se observa que el serbio
no usa el posesivo para referirse a las
partes del cuerpo, stomaku (‘estómago’), mientras que el inglés sí
lo utiliza, my stomach (‘mi estómago’), de ahí que el error en ‘mi
estómago’ sea transferencia del inglés y no del serbio. Sin embargo, siguiendo
a Leonetti, el artículo determinado español aparece en lugar del posesivo en los contextos que permiten recuperar
por otros medios, gramaticales o puramente inferenciales, la información aportada
por el posesivo,
por lo que las construcciones que denotan partes
del cuerpo exigen
su uso (2000:
809).
En cuanto a la situación inversa, los errores que reflejan la falsa
selección del artículo en lugar del determinante posesivo (A), su valor
es del 13 %. La causa principal de estos errores es el desconocimiento de
las reglas. No hay interferencia del serbio,
dado que esta lengua
utiliza el posesivo en contextos análogos al español.
El enunciado:
De pequeño
quería a visitar
Australia. Me fascina
la naturaleza de este país y *las
ciudades [...]10
9 Corpus 2011/I, redacción I/17.
10 Corpus
2011/I, redacción I/9.
En serbio correcto
se expresa con el enunciado:
Od malena sam želeo da posetim Australiju. Fascinira me poriroda ove zemlje i njeni11
gradovi [...]
“Desde pequeño quería a visitar Australia. Fascina me naturaleza de este país y sus
ciudades [...]”
En la traducción palabra por palabra del serbio al español se observa que el serbio usa el posesivo njeni (‘sus’), al igual que el español, por
lo que no hay transferencia negativa
de la lengua materna.
La relación entre el artículo y el demostrativo no se muestra como
problema en los informantes de
primer curso presentes en el corpus 2011, pues no han aparecido errores en su selección.
2.2.2
Errores de falsa selección
del II año, corpus 2011
El corpus 2011 muestra que los estudiantes de segundo curso siguen
teniendo dudas al seleccionar el artículo determinado en lugar del
posesivo (A) o en la situación inversa, la selección del posesivo en
lugar del artículo (B). Por otra parte, han superado
la relación del artículo determinado con el indeterminado, por lo que el
número de errores ha disminuido sustancialmente. Presentamos a continuación su distribución en la tabla y en el gráfico
que siguen.
|
A. Selección del artículo determinado
en lugar
de otro determinante
|
Valor del error en porcentajes
|
|
el, la (en lugar de un, una)
|
40 %
|
|
el,
la (en lugar de mi, tu, su)
|
50 %
|
|
el,
la (en lugar de este,
ese, aquel)
|
0 %
|
|
el,
la (en lugar de algún, alguna)
|
0 %
|
|
el,
la (en lugar de varios)
|
10 %
|
|
B. Selección de otro determinante
en lugar
del artículo determinado
|
Valor del error
en porcentajes
|
|
un, una (en lugar
de el, la)
|
25 %
|
|
mi,
tu, su (en
lugar de el, la)
|
75 %
|
|
este,
ese, aquel (en lugar de el, la)
|
0 %
|
|
algún,
alguna (en lugar de el, la)
|
0 %
|
Tabla 4. Errores fosilizados de falsa selección, II año, corpus
2011 (Fuente: VRS)
11 El vocablo njeni, ‘sus’, en serbio es un pronombre posesivo que indica
que el poseedor es de
tercera persona singular femenino porque el poseedor zemlja, ‘país’, es un sustantivo femenino en singular. Al mismo tiempo,
indica que el objeto poseído es de género masculino en plural porque
gradovi, ‘ciudades’, es en serbio un sustantivo masculino en plural.
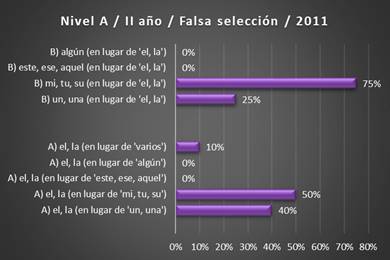
Gráfico 7. Errores fosilizados de falsa selección, II año, corpus
2011 (Fuente: VRS)
El cómputo de los
errores de falsa selección cometidos por los estudiantes del segundo curso del corpus 2011, así como su comparación con
los resultados relativos al primer curso
del mismo corpus
2011, muestra que el mayor
problema reside en la relación entre el artículo
determinado y el determinante posesivo:
la falsa selección del grupo B), selección del posesivo en lugar del artículo, constituye
el 75
% de todos los
errores, mientras que en el primer curso su valor llegaba al 50 %. El cálculo
de la situación inversa, la de los errores de falsa selección
del artículo en lugar del posesivo, muestra
que los errores fosilizados llegan al 50 %, mientras
que el curso anterior su valor era del 13 %.
La estadística de
la relación entre el artículo determinado y el artículo indeterminado muestra que hubo mejoría en el segundo curso con
respecto al primero, pues el valor de los errores fosilizados ha disminuido: la falsa selección
del artículo determinado en lugar del indeterminado es del 40 % en el
segundo curso, frente al porcentaje del primero, que alcanzaba el 88 %; el caso inverso, la falsa
selección del artículo indeterminado en lugar del determinado, es del 25 % en el segundo curso, mientras que en el
primero era del 50 %. Cabe advertir que ha
aparecido un escaso porcentaje, el 10 %, de la selección errónea del artículo determinado en lugar del determinante indefinido ‘varios’.
Por lo que se refiere
a la relación entre el demostrativo y el artículo
determinado, este corpus
2011/II curso no ha registrado ningún error, al igual que el corpus 2011 del primer
curso.
2.2.3
Recopilación de los errores de falsa selección: primer-cuarto curso, corpus 2011
Para completar el
análisis de los errores de falsa selección del presente corpus 2011,
hemos recopilado los errores del primer al cuarto año de estudio. Al igual que en el
corpus anterior, el objetivo de esta recopilación es averiguar cómo avanza esta problemática desde el primer hasta el cuarto
curso. Nos interesaba averiguar si su
porcentaje disminuía con el tiempo o si, por el contrario, crecía. En los dos gráficos
siguientes presentamos el índice de sus valores, así como sus tendencias en el
trascurso de los cuatro años lectivos.
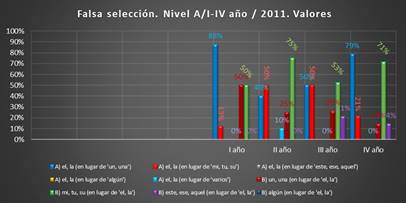
Gráfico 8. Valores. Falsa selección, I-IV año,
corpus 2011 (Fuente: VRS)
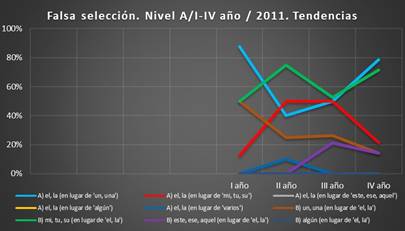
Gráfico 9. Tendencias. Falsa selección, I-IV año, corpus
2011 (Fuente: VRS)
Los gráficos indican que uno de los mayores problemas de los informantes
del corpus 2011 es la falsa selección del artículo determinado en lugar del indeterminado (grupo A). Los errores
de esta clase en el primer curso suman hasta el 88 %, en el segundo y el tercero oscilan
entre el 40 % y el 50 %; sin embargo, en el cuarto aumentan y llegan
al 79 %.
El segundo problema lo presenta la relación entre el artículo determinado
y los determinantes posesivos. Según
muestran los cálculos, el grupo B), falsa selección del posesivo en lugar del artículo, produce más problemas
que el error opuesto A), la falsa seleción del artículo en lugar del posesivo. El porcentaje de los errores
del grupo B) en el primer curso es del 50 %, en el segundo crece hasta el 75 %, en el tercer curso disminuye al 53 %; no obstante, en el
cuarto de nuevo sube al 71 %. El grupo
A), el de la falsa selección del artículo en lugar del posesivo, presenta menos problemas y en el cuarto curso disminuye al 21 % (el primer
curso es del 13 %; el segundo,
del 50 %; el tercero
muestra el 50 %).
El grupo B), el
de la falsa selección del artículo indeterminado en lugar del determinado,
a inicios de los estudios produce problemas (el 50 % en el primer año), más tarde los errores
disminuyen y oscilan
entre el 25 % y 26 % (segundo y tercer curso
respectivamente), y en el cuarto curso se quedan con un 14 %.
En el tercer
curso aparece una muestra del error de falsa selección del demostrativo en lugar del artículo (el 21 %) que en el cuarto disminuye al 14 %.
El resto de los errores están solucionados en el cuarto curso.
2.2.4
Puntos en común del primer al cuarto curso,
corpus 2011
Para observar
cuáles son los problemas que comparten todos los cursos, hemos elaborado un gráfico con los puntos en común que representa gráficamente los mayores problemas de los informantes del corpus 2011.
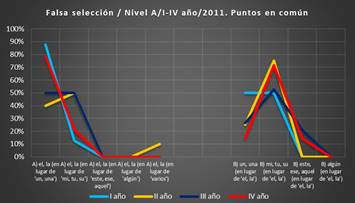
Gráfico 10. Puntos
en común. Falsa selección, I-IV año, corpus
2011 (Fuente: VRS)
El gráfico nos exhibe que la falsa selección produce determinada inseguridad
en los estudiantes de todos los cursos. Sus dudas coinciden en los siguientes
casos:
Grupo A), falsa selección del artículo determinado en lugar de otro determi-
nante:
-
Falsa selección
del artículo determinado en lugar del indeterminado (88 %, 40 %, 50 %, 79
%).
-
Falsa selección
del artículo determinado en lugar del posesivo (13 %, 50 %, 50 %,
21%).
Grupo B), falsa selección
de otro determinante en lugar del artículo
determinado:
-
Falsa selección del posesivo en lugar del artículo (50 %, 75 %, 53 %, 71
%).
-
Falsa selección
del artículo indeterminado en lugar del determinado (50 %, 25 %, 26 %, 14
%)
-
Falsa
selección del demostrativo en lugar del artículo determinado (0 %, 0 %, 21
%, 14 %).
2.3
Recapitulación
de los errores de falsa selección del cuarto curso, corpus 2014 y 2011
En este apartado exponemos una recapitulación de los errores
de falsa selección que aparecen en ambos corpus,
el 2014 y el 2011,
al final de los estudios.
El objetivo de este análisis es, por una parte, determinar si los diferentes corpus, con distintos temas de redacción, coinciden
en los problemas que presenta
la selección del artículo determinado en lugar de otro determinante o la selección de otro determinante en vez del artículo
determinado; y, por otra, comprobar si existen contenidos que se han quedado sin resolver.
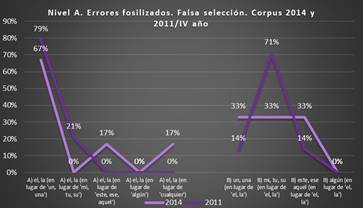
Gráfico 10.
Puntos en común. Falsa selección, I-IV año, corpus 2011 y 2014 (Fuente: VRS)
La investigación
realizada en ambos corpus ha mostrado que esta materia, relativa al Nivel A de competencia, produce determinados problemas a los estudiantes serbios de español en el transcurso de toda la carrera.
El cómputo, así como los puntos en común, se ven reflejados en el gráfico
siguiente.
El cómputo de los errores fosilizados de falsa selección, así como las
líneas de coincidencias, muestran que el mayor problema que tienen los estudiantes al final de sus estudios
es la falsa selección del artículo determinado en lugar del artículo indeterminado
(grupo A); el corpus 2011 indica el 79 % y el 2014 presenta el 67 % de
los errores.
Los dos corpus coinciden
en los errores del grupo B del modo siguiente:
-
El uso erróneo del
posesivo en lugar del artículo determinado: el corpus 2011 muestra un porcentaje considerablemente
alto, el 71 %. El corpus 2014 exhibe un valor del 33 % de estos
errores.
-
La
falsa selección del artículo indeterminado en lugar del determinado: el corpus
2014 muestra el 33 %, el corpus 2011 presenta el 14 %.
-
La falsa selección
del demostrativo en lugar del artículo determinado, el corpus 2014
presenta el 33 % y el 2011 muestra el 14 %.
-
Otros errores
de falsa selección aparecen en uno o en el otro corpus, y su valor varía
entre el 21 % y el 17 %.
3. Conclusiones
Hemos concluido que existen dos causas principales que propician los
errores relativos a la relación entre el artículo y los
demostrativos y a la relación entre el artículo y los posesivos:
1. Grupo A), la falsa selección del artículo determinado en lugar del demostrativo o posesivo, por lo general se debe al
desconocimiento de las reglas gramaticales del
español:
-
La falsa selección del artículo
en lugar del demostrativo: en español, según
Leonetti, la diferencia más evidente entre el uso del demostrativo frente al uso del artículo determinado consiste en que el
demostrativo exige que el referente sea perceptible de alguna forma en la situación de habla
(2000: 800). En Las clases con nuestra profesora al principio me
parecían muy aburridos, pensaba que tenemos demasiadas cosas para
aprender, tanto palabras como reglas, pero después empecé a querer *la
asignatura la versión correcta, ‘esa asignatura’, es equivalente al serbio, taj predmet (‘esa asignatura’), es decir,
ambas lenguas usan el demostrativo: el español, porque
el referente es perceptible en el discurso; el serbio, porque
se vale de la función
anafórica de sus demostrativos. De ahí que no haya interferencia del serbio, debido
a que esta lengua en contextos
equivalentes también usa el demostrativo
valiéndose de la función anafórica de sus demostrativos.
-
La falsa selección del artículo en lugar del posesivo:
en español, siguiendo
a Leonetti, para que el
artículo aparezca en lugar del posesivo, el poseedor debe estar
reflejado en un constituyente externo al sintagma nominal definido (2000: 809) (Los clases de la historia hispanoamericana
están interesantes también para mí, porque quiero conocer bien los lugares que existen en España y
*las personas famosas tambien). El serbio, en
contextos análogos, aplica normas equivalentes al español, por lo que no hay transferencia negativa del serbio.
2. Grupo B), los errores de falsa selección del
demostrativo o del posesivo en lugar
del artículo se deben muchas veces a la interferencia del serbio o a la interferencia de alguna lengua
extranjera que el estudiante conoce.
-
La falsa selección del demostrativo en lugar del artículo: la causa reside
en la
interferencia de la lengua materna, además
de en el desconocimiento de las normas del español. En La obra que más me gusta, de *estos que
habíamos leído, es La Celestina; Delo koje mi se najviše sviđa, od on-ih koje smo čitali, je La Selestina; “Obra que a mí me más gusta, de aquellos que
hemos leído, es La Celestina”, el estudiante se vale de la función anafórica de los demostrativos serbios ovaj (‘este’), taj (‘ese’) y onaj (‘aquel’), y la traduce
directamente al español,
por lo que se observa
la interferencia de la lengua
materna. Por otro lado, desconoce la norma del español de que los demostrativos no
pueden emplearse en primera mención si el sustantivo al que determinan va con modificadores restrictivos.
-
La falsa selección del posesivo
en lugar del artículo: la interferencia del inglés y no del serbio, es sobre todo evidente en la selección
errónea del posesivo en lugar del artículo determinado. Son errores que se arrastran hasta finales del cuarto año de estudio
y constituyen el 33 % y el 71 % de los errores, computados en el corpus
2014 y en el 2011, respectivamente (Abro *mis ojos12 frente a I open my eyes). En este caso,
habría que tener en consideración que se trata de una característica propia del español, puesto que
el
español muestra una clara preferencia por el empleo del artículo definido en contextos
gramaticales en los que en principio cabría el uso del posesivo, peculiaridad en la que el español contrasta con las
lenguas germánicas e incluso con otras lenguas
románicas como el francés (Leonetti, 2000: 808)
Cabe
observar que, a la hora de realizar
el corpus 2014, entregamos un cuestionario a los estudiantes universitarios de español del primer, segundo,
tercer
12 Corpus 2011, redacción II/2.
y cuarto curso, los cuales
tenían como niveles de competencia A1-A2, B1, B2 y C1, respectivamente. El cuestionario lo realizamos con el fin de
conocer las necesidades de los
estudiantes serbios y elaborar unas implicaciones didácticas que sirvieran para subsanar los errores registrados. En
este sentido, les proporcionamos la pregunta ¿Te ayuda el contraste gramatical del español con el serbio u
otras lenguas extranjeras? Los cálculos de la encuesta mostraron que
la mayoría de los estudiantes sostenía que el contraste con su lengua materna
o con una lengua extranjera que conocían les ayudaba en la adquisición del español. Las respuestas del sí varían
entre el 50 % y el 86 %. La mayoría optó por el contraste con el serbio; no
obstante, llama la atención la opción que escogió
la muestra del primer curso: la mayoría de estos estudiantes considera que el contraste con el inglés les ayuda en la adquisición del español.
Por otra parte,
el análisis de los errores ha mostrado que precisamente el contraste del español con el inglés es el
que conduce a los estudiantes del primer curso a cometer errores de falsa selección,
concretamente, la selección errónea del posesivo
en lugar del artículo determinado. Por lo que atañe al contraste del español con el serbio, el análisis
contrastivo y el análisis de los errores han mostrado que ambas lenguas poseen
puntos comunes en la mayoría
de los contenidos y que para una mejor compresión y adquisición del artículo español
es importante contrastar ambas.
Finalmente, se
infiere que los dos métodos de la lingüística contrastiva, el análisis
contrastivo y el análisis de errores, son complementarios y solo combinados ofrecen resultados de investigación útiles, pues hay contenidos referidos
al artículo y, específicamente, a la falsa selección,
en los que nos hemos percatado de que los mecanismos
que utilizan las dos lenguas son equivalentes, y de ahí hemos concluido que el análisis
contrastivo es útil; por otra parte, hay casos en los que el análisis
de los errores ha mostrado que, aunque existan equivalencias entre las
lenguas y pareciera que los estudiantes no deberían cometer
errores, estos ocurren.
Bibliografía
FERNÁNDEZ, Sonsoles. Interlengua y análisis de errores en el aprendizaje del español como lengua extranjera. Madrid: Edelsa Grupo Didascalia,
S.A., 1997.
INSTITUTO CERVANTES. Plan curricular del Instituto Cervantes. Niveles de referencia para el español. Madrid: Instituto Cervantes
y Editorial Biblioteca Nueva, S.L., 2006.
LEONETTI, Manuel. “El artículo”. Gramática descriptiva de la lengua española. Dirs. Ignacio
Bosque y Violeta Demonte. Vol. 1. Madrid:
Espasa Calpe, S.A., 2000. 787-890.
MARTÍ SÁNCHEZ, Manuel et al. Gramática española
por niveles. Madrid:
Editorial Edinumen, 2008.
PIPER, Predrag y KLAJN Ivan. Normativna gramatika srpskog jezika ‘Gramática normativa de la lengua serbia’. Novi Sad: Matica
srpska, 2014.
REAL ACADEMIA ESPAÑOLA. Nueva Gramática de la Lengua
Española (Morfología.
Sintaxis
1). Madrid: Espasa
Libros, S.L.U., 2009.
---. Nueva Gramática de la Lengua
Española. Manual. Madrid: Espasa Libros, S.L.U.,
2010.
RUBINJONI STRUGAR, Vlatka. Análisis de
errores en el uso del artículo determinado en
producciones escritas de aprendientes serbios de español
como lengua extranjera. Tesis
doctoral. Alcalá
de Henares: Universidad de Alcalá, 2017. <https://ebuah.uah.es/dspace/ handle/10017/19743>
[20/05/2019]
---. El serbio, una muestra para lenguas sin
artículo determinado. Belgrado: Studio Strugar
Editores, 2018.
SANTOS GARGALLO,
Isabel. Análisis contrastivo, Análisis de
Errores e Interlengua en el marco de la Lingüística Contrastiva. Madrid: Editorial
Síntesis, 1993.
VÁZQUEZ, Graciela
E. Análisis de errores
y aprendizaje de español / lengua extranjera. Frankfurt am Main: Verlag Peter Lang GmbH, 1991.
ZEČEVIĆ KRNETA, Gorana. Upotreba određenog člana u španskom kao stranom
jeziku na osnovu analize grešaka
kod govornika srpskog jezika. Tesis doctoral. Kragujevac:
Univerzitet u Kragujevcu, 2016. <https://phaidrakg.kg.ac.rs/detail_object/o:777?tab=0#mda> [15/12/2016]